Jacob Morrow
Updated: 2026-05-22
In financial services, a typical high-pressure window is easy to picture: peak trading hours, the post-change monitoring period after routine releases, or a Downtime failover window. The notifications that matter in these moments are rarely “nice-to-have.” They are OTP verifications, transaction risk alerts, account security warnings, and service incident notices. Any delay or loss shrinks the response window.
For regulated financial institutions, the requirement is straightforward:
- “Send success” is not enough.
- You need verifiable delivery outcomes.
- You need an Audit Trail that can withstand compliance review.
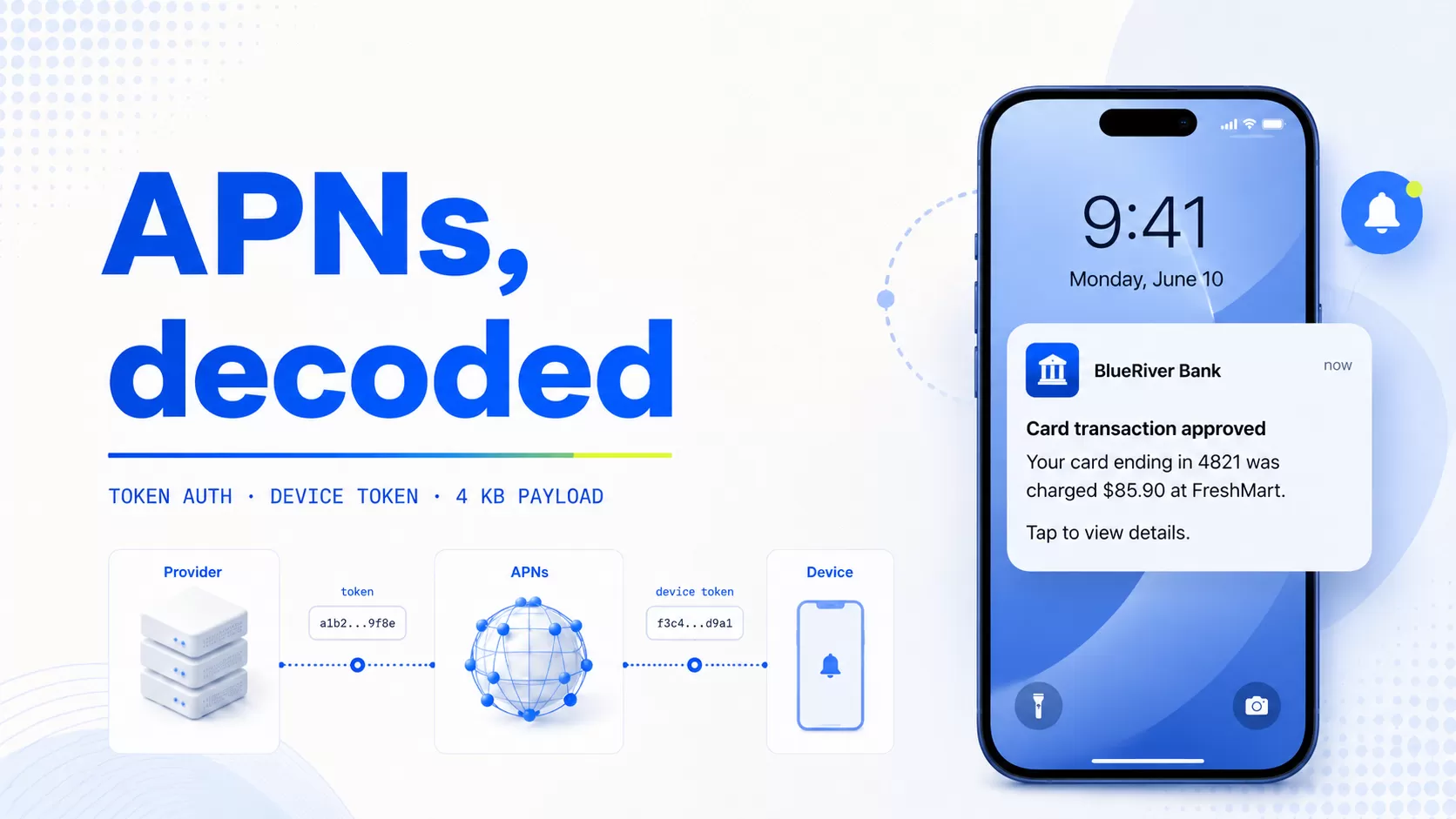
The blind spot sits between “sent” and “actually seen and acted on.” Many teams think they are managing “delivery rate,” but in practice they are only looking at server-side events. Between backend “sent” and user-side display, there is a gray zone that is hard to observe, hard to reconcile, and hard to audit—the push blind spot.
Downtime and partial failures amplify the risk. Without a clear disaster recovery retry mechanism and a reviewable evidence chain, you will struggle to answer three audit questions: when it was dispatched, which route it took, and which retry/compensation policy was applied. In this context, Zero Data Loss is not a slogan—it is a system-level requirement for event logging, replayability, and end-to-end auditability.
This article follows common cross-border scenarios in Hong Kong and organizes the key risks and governance actions by audit attention points and control measures (focused on controllability, traceability, and auditability, while keeping the overall structure intact).
Let’s Define It Clearly: What Is a “Push Blind Spot”?
A push blind spot is not “nothing gets delivered.” More often, it looks like this:
- The backend shows “submitted / dispatched”
- The system considers the job complete
- The user device does not show it in time (muted, delayed into summaries, expired while offline, etc.)
In short, the blind spot is that you measure server events, not user outcomes.
Key Takeaway: For regulated financial institutions, governance must cover the full end-to-end path: dispatch → device receipt → display → open/action, not a single “send success” checkpoint.

Audit Attention Point 1: Mistaking “FCM Availability” for Guaranteed Cross-Border Push Delivery
In Hong Kong, two realities commonly coexist:
- Android devices with full Google Play services (FCM is usually available)
- Android ecosystems without GMS, China ROMs, or heavily customized builds (FCM is not the only answer)
Once a cross-border app meets a more complex device distribution, a single-path push strategy can create a black hole where “a certain segment simply never receives it.”
- Risk: Channel coverage is incomplete; ecosystem fragmentation is underestimated.
- Impact: A specific cohort becomes unreachable during critical windows, often without reliable reproduction in test environments.
- Control measure: Segment by device/ROM/region, measure coverage and display rates, and implement a traceable routing rule set plus a fallback path (not “retries only”).
How to Validate Whether You’re in This Blind Spot
Ask three questions:
- Can you clearly segment which devices go via FCM and which require alternative paths?
- Can you see display-rate differences when broken down by brand/ROM/region?
- Do you have a defined fallback path, rather than just repeated retries?
Audit Attention Point 2: Android Fragmentation and OEM Notification Policies Turn Inactive Users into a Delivery Black Hole
For financial apps, the highest-risk population is often not power users, but “low-frequency, high-importance” cases:
- The app is rarely opened, but OTP or risk alerts must work when needed
- After device changes, updates, or background cleanup, permissions and background behavior may be reset
Battery optimization, background restrictions, and OEM-level policy changes can degrade an app’s notification behavior when the app is inactive.
- Risk: Background controls reduce receipt and/or display reliability.
- Impact: Users who are inactive become unreachable precisely when it matters; post-incident reviews often only show “no click,” with no clear breakpoint.
- Control measure: Treat inactive users as a first-class scenario in monitoring and drills; receipt, display, expiry, and retry outcomes must be traceable.
Audit Attention Point 3: iOS Focus Turns “Immediate Alerts” into “Muted Alerts”
iOS Focus is not a niche feature. For executives and professionals, it is routine: work, meetings, sleep, commuting—each mode can mute an app’s notifications.
Apple’s documentation is clear: Focus allows users to choose which apps’ notifications are allowed or silenced (see Apple Support: “Allow or silence notifications for a Focus,” iOS user guide).
- Risk: OS policy-layer blocking creates a “delivered but not displayed” gap.
- Impact: Critical alerts are seen later; the response window shrinks; a provider receipt alone cannot prove the user saw the notification.
- Control measure: Classify messages (security/transaction/service/marketing), and keep the classification rationale and policy changes in the Audit Trail.
Audit Attention Point 4: iOS Notification Summary Converts Timeliness into a Schedule
Notification Summary can batch notifications and present them at user-defined times. For time-sensitive financial messages, that is a serious risk: what you think is an “immediate alert” may effectively become “later.”
- Risk: Summary scheduling shifts time-sensitive alerts into delayed delivery windows.
- Impact: “Immediate alert” expectations fail at the display layer.
- Control measure: Use clear classification and policy alignment to reduce misclassification; record “summarized / delayed” outcomes as traceable status signals.
Audit Attention Point 5: Monitoring “Send Rate” Without Monitoring “Display” and “Arrival”
Many dashboards look impressive: volume, send success, clicks. But from a compliance audit perspective, this often remains “the system talking to itself.”
- Risk: Measuring “sent” only; missing an end-to-end evidence chain.
- Impact: After an incident, you cannot reconstruct where it failed; you also cannot provide reviewable materials to internal audit/compliance.
- Control measure: Build an Observability and logging framework and connect key events into a consistent Audit Trail:
- Dispatch layer (server → push provider): requests, receipts, error codes, retry decisions
- Device layer (device received): receipt signals and failure attribution
- Display layer (notification displayed): displayed/muted/summarized/expired outcomes
- Behavior layer (open/click): behavior and time window
- Business layer (OTP completion, transaction confirmation): alignment and reconciliation
Audit Attention Point 6: When Compliance and Data Governance Lag, Teams Default to “Sending Less”
- Risk: Governance gaps force conservative behavior as a substitute for control.
- Impact: Critical messages cannot be delivered systematically; audit materials are insufficient.
- Control measure: Implement governance in the language regulated institutions use (HKMA/PDPO requirements):
- Classify message types (security/transaction/service/marketing)
- Define allowed channels, storage/retry policies, and exception handling for each level
- Make permissions and change management traceable
⚠️ Warning: This article is not legal advice. For PDPO/GDPR or cross-border transfer requirements, consult your compliance/legal team.
Audit Attention Point 7: “Retry” Is Not Reliability—Retries Without a DR Retry Mechanism Increase Uncontrolled Cost
- Risk: Treating retries as a universal remedy.
- Impact: Retries can be ineffective when the device is offline; during failures, they can increase duplicate notifications and operational cost.
- Control measure: Make retries a governed disaster recovery retry mechanism:
- Multi-path and failover: backup channels and failover logic
- Policy-driven retries: define retry conditions and caps by message class
- Compensation and reconciliation: complete compensation within time windows
- Observability: connect all decisions into a complete Audit Trail
Next Step: Use an “Assessment Checklist” to Make the Blind Spot Measurable and Controllable
Use this checklist to align stakeholders:
- Can you segment and cover different ecosystems (FCM/APNs/OEM/HarmonyOS, etc.)?
- Can you measure end-to-end metrics (at least dispatch and display)?
- Can you implement message classification and bind governance rules?
- Do you have a clear disaster recovery retry mechanism for Downtime?
Learn More (For Licensed Financial Institutions)
If you are evaluating how to reduce cross-border push blind spots to a controllable level, you can visit the licensed financial institutions page to review the solution and implementation path:
Learn More